Technical Report: Integrating Custom Haskell Functions with SQL Engines (SQLite, PostgreSQL, MySQL)
1. Introduction
At DPella, we leverage advanced programming language techniques in Haskell, particularly its powerful type system, to develop robust and correct-by-construction applications. However, while Haskell excels in enforcing complex invariants with type safety, it is not ideally suited for processing large volumes of data. In contrast, relational databases are designed for efficient data management and processing. In this repository, we explore how we can offload data processing tasks to relational databases while utilizing Haskell’s capabilities for injecting noise into the data.
The primary goal of this repository is to establish effective communication between the Haskell runtime and the database engine runtime, enabling the execution of Haskell logic directly within SQL queries. We focus on integrating custom functions with both embedded databases like SQLite and external databases such as PostgreSQL and MySQL.
The next figure shows the general idea of the project.
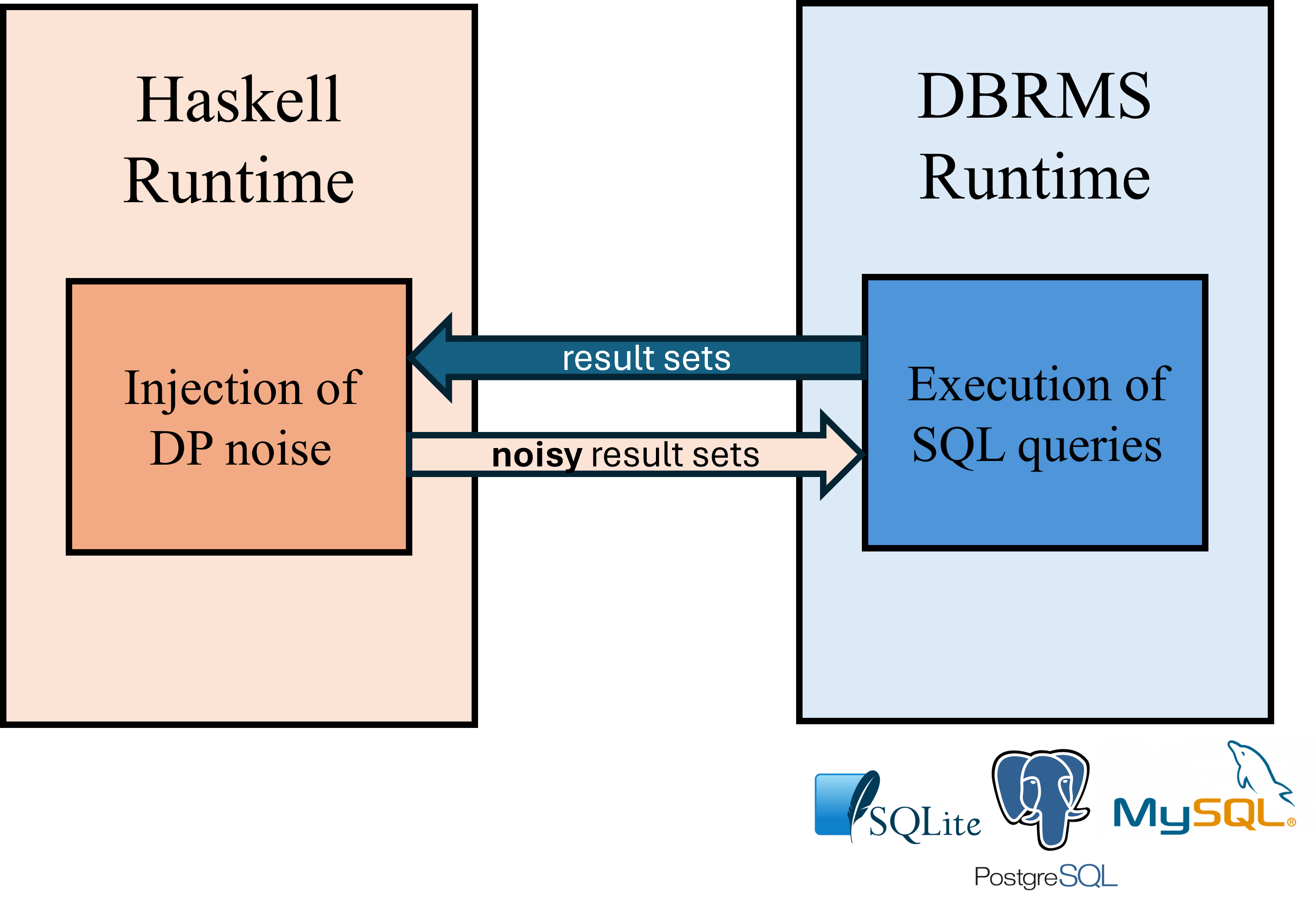
The DBRMS will send data – often the result of certain data analyses – when running SQL queries to DPella’s implementation. DPella will *inject noise to those results to protect the privacy of the individuals contributing with their data to the dataset being analyzed – DPella applies Differential Privacy technology for this. The resulting noisy results and then send back to the engine for further processing if needed.
Generally speaking, this report details and compares methods for DBRMS being able to call functions written in the Haskell. We evaluate three popular SQL database engines: SQLite, PostgreSQL, and MySQL. The primary goal is to enable the execution of Haskell logic by SQL queries, such as complex algorithms or specialized computations like adding Differential Privacy noise. By doing so, developers can leverage Haskell’s strengths (e.g., type safety, functional purity) within their existing database workflows.
2. Motivating example
We will zoom in into the architecture shown above with a concrete example that will be used in the rest of the report.
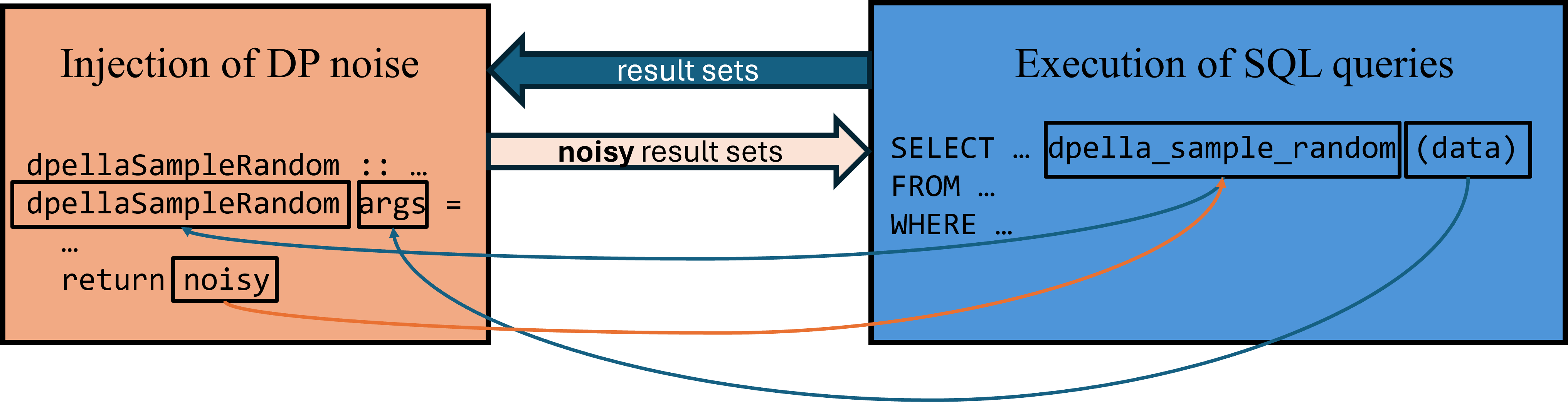
The example focuses on SQL queries being able to call the Haskell function
dpellaSampleRandom (implemented in Noise.hs) which
generates a random number within a given range, potentially as part of a
Differential Privacy mechanism. This function requires managing state (the
random number generator) across calls.
To call that function, queries use the SQL function dpella_sample_random. The
challenges here are three-fold: (i) to make the DBRMS to connect the SQL function
dpella_sample_random with the code in dpellaSampleRandom; (ii) passing all
the SQL arguments as dpellaSampleRandom’s arguments; and (iii) passing the
result of dpellaSampleRandom as the SQL result of dpella_sample_random.
Running example
Set up the environment (builds Docker image with dependencies and extensions) by running the following command in the root directory of the repository:
docker build -t sql-interoperability-example .
We consider a table of employees, where each row contains the name of the employee, their age, and a boolean flag to indicate if they are still employed (see code in Main.hs).
The example creates the table of employees, inserts some hard coded records, and executes the following query four times – so that randomness can be seen.
SELECT SUM(CAST(age as FLOAT)) + dpella_sample_random(CAST(18 AS FLOAT),CAST(67 AS FLOAT))
FROM employees
This query obtains the sum of all the ages and then adds a random number
between 18 and 67. The reason to include AS FLOAT in the constants above
is connected to data marshalling across the DBRMS and Haskell (explained
later).
Run the example (executes Main.hs within the Docker container):
docker run sql-interoperability-example
The following output shows how we run such SQL operations in three different SQL engines, i.e., SQLite, Postgres, and MySQL.
--- Running SQLite Example ---
SQLite table 'employees' created.
Inserted 4 records into SQLite.
Sum of ages (with noise) (SQLite): 171.1366419561398
Sum of ages (with noise) (SQLite): 148.75287169458687
Sum of ages (with noise) (SQLite): 160.61467033334398
Sum of ages (with noise) (SQLite): 158.95724915195856
--- Running PostgreSQL Example ---
Connecting to: postgres://test:test@localhost:5432/test
PostgreSQL table 'employees' created.
Inserted 4 records into PostgreSQL.
Sum of ages (PostgreSQL): 166.50913874804027
Sum of ages (PostgreSQL): 190.64541265429347
Sum of ages (PostgreSQL): 190.05762465442217
Sum of ages (PostgreSQL): 183.1843888581907
--- Running MySQL Example ---
Connecting to: mysql://test:test@localhost:3306/test
MySQL table 'employees' created.
Inserted 4 records into MySQL.
Sum of ages (MySQL): 153.09850998336447
Sum of ages (MySQL): 150.8886262387034
Sum of ages (MySQL): 152.52728376912134
Sum of ages (MySQL): 176.15142166159143
In what follows the report outline the distinct integration architecture required for each engine, analyses common components across the Haskell modules for interoperability. Files SQLite.hs, Postgres.hs, and MySQL.hs provide the required infrastructure (e.g., types, monads) to run the SQL instructions described in Main.hs, and presents a comparative analysis of the approaches.
3. Overview
This repository demonstrates how to call to Haskell’s code when
executing the SQL function dpella_sample_random across the DBRMS
SQLite, PostgreSQL, and MySQL. At the top level, the approach consists
on the following parts:
-
Defining the Haskell function that gives semantics to the SQL function
dpella_sample_random(dpellaSampleRandomin Noise.hs) and its state (of typeNoiseGen). -
Providing Haskell interoperability modules SQLite.hs, Postgres.hs, and MySQL.hs. All three modules provide a monadic interface for interacting with their respective DBRMS.
Each module includes functions to establish and manage database connections.
runSQLiteT :: (MonadIO m) => FilePath -> SQLiteT m a -> m a runPostgresT :: (MonadIO m) => BS.ByteString -> PostgresT m a -> m a runMySQLT :: (MonadIO m) => BS.ByteString -> MySQLT m a -> m aSQLiteT,PostgresT, andMySQLTare all monad transformers that extend the base monad (oftenIO) to include additional functionality specific to their respective database operations.These modules also support executing SQL queries, i.e.,
SELECT,SQLite.query_ :: (SQLite.FromRow res, MonadIO m) => SQLite.Query -> SQLiteT m [res] Postgres.query_ :: (Postgres.FromRow res, MonadIO m) => Postgres.Query -> PostgresT m [res] MySQL.query_ :: (MySQL.QueryResults res, MonadIO m) => MySQL.Query -> MySQLT m [res]as well as SQL instructions that modify the dataset, e.g.,
UPDATE,INSERT, andCREATE. However, to run those instructions, it is needed another set of functions which receive an extra argument (res) of the data to be inserted.SQLite.execute :: (SQLite.ToRow res, MonadIO m) => SQLite.Query -> res -> SQLiteT m Int Postgres.execute :: (Postgres.ToRow res, MonadIO m) => Postgres.Query -> res -> PostgresT m Int MySQL.execute :: (MySQL.QueryParams res, MonadIO m) => MySQL.Query -> res -> MySQLT m IntThe modules also have functions to manage transactions and error handling but we do not describe them any further.
-
Making the DBRMS aware of the SQL function
dpella_sample_randomand which code to execute when being called. This tasks is implemented using SQL engine-specific mechanisms and are described below.
3.1 SQLite
Since it is an embedded DBRMS, it runs within the same process as the Haskell
application defined in Main.hs. SQL custom functions,
e.g., dpella_sample_random, are directly registered using the API from the
Haskell package sqlite-simple (see function DPella.SQLite.withSQLFunctions).
This allows seamless invocation of Haskell functions from SQL queries via
query_, as seen in runSQLiteExample in Main.hs.
sumQuery :: IsString a => a
sumQuery = "SELECT dpella_sample_random(SUM(CAST(age as FLOAT)),CAST(10 AS FLOAT))"
++ " FROM employees"
-- It declares the custom SQL function `dpella_sample_random`, and
-- provides the semantics as the Haskell function `dpellaSampleRandom`
sqlDPellaSampleRandom :: SQLFunction
sqlDPellaSampleRandom =
SQLFunction "dpella_sample_random" $ dpellaSampleRandom . sqlite_env_rng
runWithSampling = do
-- Initialized the random seed
env <- liftIO initSQLiteEnv
-- Get the connection
conn <- getConnection
-- Register the function
SQLite.createFunction conn sqlDPellaSampleRandom (impl env)
-- Running the query
query_ sumQuery
3.2 PostgreSQL
As a stand-alone DBRMS, it runs in a separate process as the Haskell code. Integration is achieved by creating a PostgreSQL extension (see folder dpella-ffi-ext/pg_extension) as a shared library written in C (dpella-ffi-ext.c).
Intuitively, Postgres will call into the C function
pg_dpella_sample_random in the extension when hitting the SQL function
dpella_sample_random. This information is defined for the Postgres extension
file dpella-ffi-ext–1.0.sql:
CREATE FUNCTION dpella_sample_random(result FLOAT8, param FLOAT8)
RETURNS FLOAT8 AS 'MODULE_PATHNAME', 'pg_dpella_sample_random' LANGUAGE C
IMMUTABLE STRICT;
This C code then calls into the C function dpella_sample_random_hs which is
exported by the Haskell FFI DPella_FFI.hs:
foreign export ccall "dpella_sample_random_hs"
wrappedDpellaSampleRandom :: CDouble -> CDouble -> IO CDouble
So, when dpella_sample_random_hs get invoked, then the Haskell function
wrappedDpellaSampleRandom gets called, which subsequently calls
dpellaSampleRandom.
wrappedDpellaSampleRandom :: CDouble -> CDouble -> IO CDouble
wrappedDpellaSampleRandom = wrap2 dpellaSampleRandom
Postgres extensions most be initialized and finished using C functions
_PG_init and _PG_fini. These functions then call the Haskell FFI provided
functions init_hs and hs_exit to initialize and finished the Haskell runtime
(dpella-ffi-ext.c):
void _PG_init(void) {
hs_init(NULL, NULL);
}
void _PG_fini(void) {
hs_exit();
}
3.3 MySQL
As a stand-alone DBRMS, it runs in a separate process from the Haskell runtime.
Custom SQL functions are dynamically loaded using MySQL’s User Defined Function
(UDF)
mechanism,
where CREATE FUNCTION defines loadable functions (see file
init.sql):
CREATE FUNCTION dpella_sample_random RETURNS REAL SONAME "libdpella_ffi_mysql.so";
When MySQL invokes dpella_sample_random, it calls functions with the same
name found in the library libdpella_ffi_mysql.so. The C source code of this
library can be found in dpella_ffi_mysql.c:
int dpella_sample_random_init(UDF_INIT *initid, UDF_ARGS *args, char *message) ;
void dpella_sample_random_deinit(UDF_INIT *initid) ;
double dpella_sample_random(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error) ;
The C function dpella_sample_random acts as bridge, calling the
FFI-exposed C function dpella_sample_random_hs:
double dpella_sample_random(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error) {
double arg1 = *((double*)args->args[0]);
double arg2 = *((double*)args->args[1]);
double result = dpella_sample_random_hs(arg1, arg2);
*((double*)initid->ptr) = result;
return result;
}
The Haskell runtime is initialized upon the first function call – see code in
dpella_sample_random_init and the call to hs_init. The C functions mentioned
above use a mutex for thread safety and remain active for the lifetime of the
MySQL process. In fact, the UDF mechanism never calls hs_exit.
4. Commonalities Across Engines
Despite differences in integration specifics, several common aspects are observed:
Modular Design: The project structure separates Haskell logic (dpella-base), FFI bindings (dpella-ffi), engine-specific Haskell interoperability modules (dpella-sqlite, dpella-postgres, dpella-mysql), and the example application (example).
Haskell interoperability modules: Each engine has a corresponding Haskell
module that provides a monadic interface built on ReaderT Connection m a,
standardizing functions for database interactions (see modules
DPella.SQLite,
DPella.Postgres, and
DPella.MySQL). The interface
provides functions for running (i.e., runSQLite, runPostgres, and runMySQL),
querying (i.e., query and query_), and modifying (i.e., execute and
execute_) the dataset.
Custom SQL Function Definition: Each integration defines the custom SQL
function named dpella_sample_random.
Haskell logic: All interoperability modules ultimately call the same underlying Haskell function, dpellaSampleRandom from Noise.hs, therefore ensuring consistent behavior across the different DBRMS.
Use of foreign function interface (FFI): Both Postgres and MySQL
integrations rely on Haskell’s FFI (foreign export ccall in
DPella_FFI.hs). In contrast, SQLite, as an
embedded DBRMS, do not need FFI since everything runs under the same process in
the Haskell runtime.
Stateful random number generation: The function dpellaSampleRandom is
stateful. It utilizes a reference of type NoiseGen (type NoiseGen = IORef StdGen)
to store the random seed. After each query, this reference gets
updates to give place to the next random number.
-
For SQLite as embedded DBRMS, this reference is managed by the environment of the reader monad, i.e., within the environment of type
SQLEnvcreated per connection inwithSQLFunctions. -
For Postgres and MySQL, as external DBRMS, state is managed by the Haskell runtime. However, Postgres and MySQL do not see the random seed, i.e., it is an internal state of the Haskell runtime. To manage that in a pure language like Haskell, the module DPella_FFI.hs defines a global non-inlineable (
NOINLINE)IORefcallednOISEGEN. The reference needs to be non-inlineable to avoid that the compiler inlines the creation of such reference at several places and ends up creating more than one. To hide this state from the API used by the DBRMS,unsafePerformIOis being used, which implies that theIORefis shared state across all connections within the database process where the Haskell runtime is loaded.
5. Detailed Report and Comparison
This repository demonstrates interoperability between Haskell and three SQL
engines. Each requires a different approach to integrate the
dpella_sample_random Haskell function. Below, we outline the integration
architecture and workflow for each engine, with their respective pros and cons.
5.1. SQLite
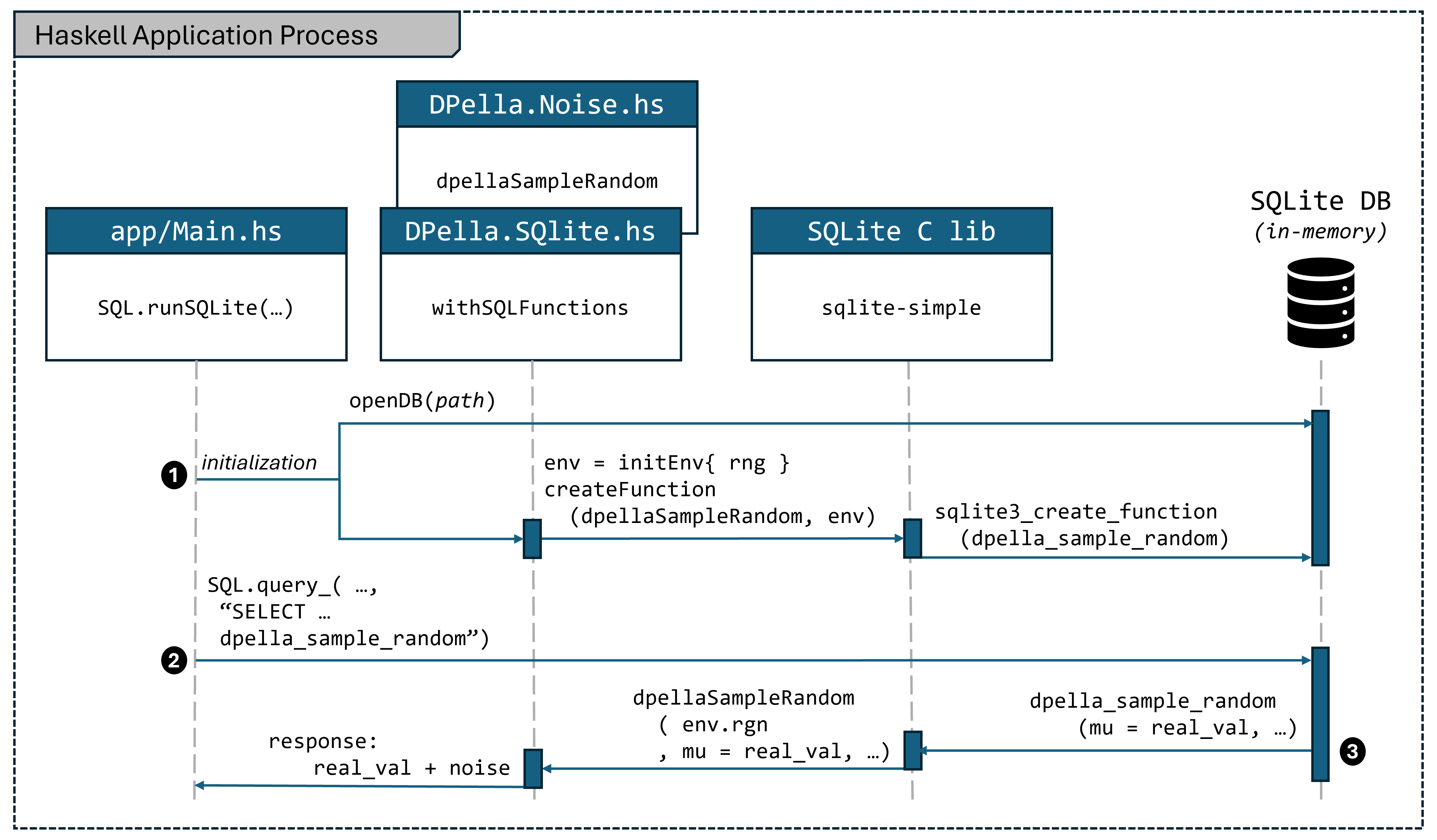
Overview
The Haskell application (app/Main.hs) initializes and connects to an
in-process SQLite database. During initialization, the application i)
initializes an SQL environment holding the stateful NoiseGen, and ii) uses the
DPella.SQLite wrapper to register the Haskell function dpellaSampleRandom as
an SQL function called dpella_sample_random. The wrapper uses the function
createFunction from the SQLite client library sqlite-simple to perform the
registration.
To execute SQL queries, the application uses the query_ function. Queries
referring to the the registered SQL function dpella_sample_random will trigger
the execution of the Haskell function dpellaSampleRandom within the same
process.
Key steps
- Initialize an SQLite environment containing the process-local state
(
NoiseGen). - Register the SQL function
dpella_sample_randomusingcreateFunction. - Execute SQL queries using
query_to call the registered function.
Details
-
Integration: SQLite runs in-process with the Haskell application. The
DPella.SQLitemodule directly registers and unregister functions usingsqlite-simple’s API. An environment (SQLEnv) holding theNoiseGenis created for the scope of the connection. -
Invocation Mechanism: The Haskell function
dpellaSampleRandomis wrapped and registered with the SQLite connection usingSQLite.createFunction. TheSQLEnvcontaining the statefulNoiseGenis passed to the implementation.-- From dpella-sqlite/src/DPella/SQLite.hs -- Defines the SQL function structure data SQLFunction where SQLFunction :: (SQLite.Function f) => FunctionName -> FunctionImpl f -> SQLFunction -- Specifies the function name and the Haskell implementation (using the env's RNG) sqlDpellaSampleRandom :: SQLFunction sqlDpellaSampleRandom = SQLFunction "dpella_sample_random" $ dpellaSampleRandom . sqlite_env_rng -- Registers the function(s) within the connection scope withSQLFunctions :: (MonadIO m) => [SQLFunction] -> SQLite.Connection -> (SQLite.Connection -> m a) -> m a withSQLFunctions funs conn ma = do env <- liftIO initSQLiteEnv -- Creates environment with NoiseGen liftIO $ forM_ funs $ \(SQLFunction name impl) -> do -- `impl env` provides the actual Haskell function IO () -> IO SQLData res <- SQLite.createFunction conn name (impl env) -- Registers the function case res of Left err -> throwIO (userError (show err)) Right () -> return () a <- ma conn -- Computation uses the function liftIO $ forM_ funs $ \(SQLFunction name _) -> do SQLite.deleteFunction conn name -- Unregisters the function return a - Usage (
app/Main.hs):runSQLiteExample :: IO () runSQLiteExample = SQL.runSQLite ":memory:" $ do -- Establishes connection and manages functions liftIO $ putStrLn "--- Running SQLite Example ---" -- ... (create table, insert data) ... -- Query sum of ages 4 times, to show randomness forM_ [1 :: Int ..4] $ \_ -> do [SQL.Only totalAge] :: [SQL.Only Double] <- SQL.query_ sumQuery -- Executes query using the custom function liftIO $ putStrLn $ "Sum of ages (with noise) (SQLite): " <> show totalAge - Pros:
- Simple integration
- Easy state management within the Haskell application context
- No external dependencies
- Cons:
- Limited scalability and concurrency due to single-process architecture
5.2. PostgreSQL
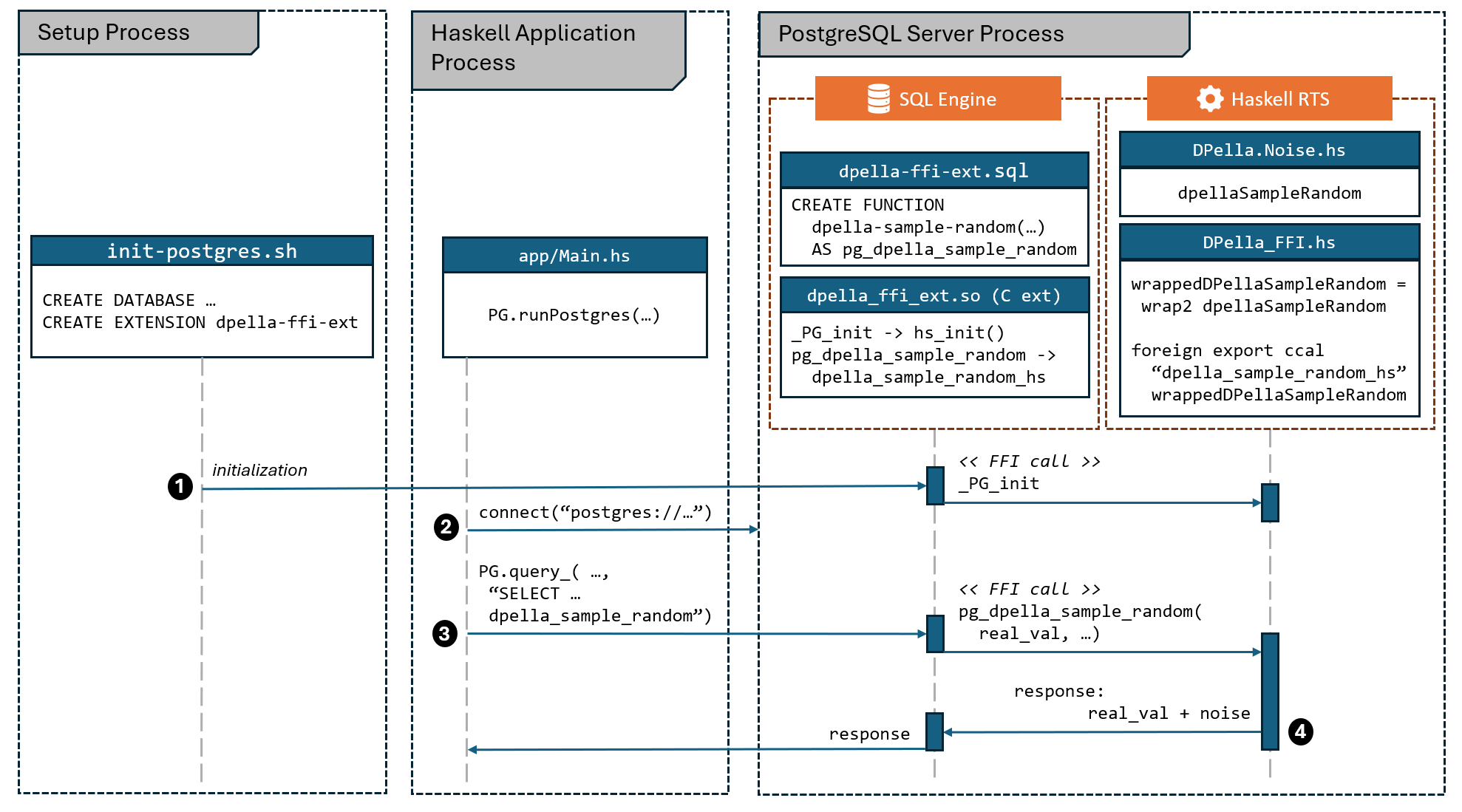
Overview
The PostgreSQL server is initialized and runs as a separate process than the
Haskell application. During initialization, a new PostgreSQL extension is
created (dpella-ffi-ext) that loads a shared library (dpella-ffi-ext.so)
containing the C function pg_dpella_sample_random. This C function is linked
to the SQL function dpella_sample_random via the SQL command CREATE
FUNCTION. The C function calls the Haskell function dpella_sample_random_hs
via the Foreign Function Interface (FFI) which maps to the wrapped
dpellaSampleRandom Haskell function. The Haskell code runs within the Haskell
Runtime System (RTS) initialized (hs_init) inside the PostgreSQL process.
To execute SQL queries, the application uses the query_ function from the
PostgreSQL client library postgresql-simple. Queries referring to the
registered SQL function dpella_sample_random will trigger the execution of the
Haskell function dpella_sample_random_hs within the PostgreSQL process.
Key steps
- Define the SQL function
dpella_sample_randomin the PostgreSQL extension file (dpella-ffi-ext--1.0.sql) via theCREATE FUNCTIONprocedure. - Load the extension into the database using the SQL command
CREATE EXTENSION. - Initialize the Haskell runtime within the PostgreSQL process using
_PG_init. - Implement the C function
pg_dpella_sample_randomto handle SQL calls and invoke the Haskell functiondpella_sample_random_hsvia FFI.
Details
-
Integration: The PostgreSQL server runs as a separate process. A C extension (
dpella-ffi-ext) is required to call the Haskell function via FFI (DPella_FFI.hs). The Haskell runtime is explicitly managed viahs_init/hs_exitin_PG_init/_PG_fini. The extension is created via SQL’sCREATE FUNCTIONprocedure (dpella-ffi-ext--1.0.sql). Lastly, the statefulNoiseGenis global within the FFI module. -
Invocation Mechanism: The SQL function
dpella_sample_randomis linked to the C functionpg_dpella_sample_random. This C function retrieves arguments and calls the Haskell functiondpella_sample_random_hs(which is the FFI export name forwrappedDpellaSampleRandom) via the FFI stub header.-- From dpella-ffi/pg_extension/dpella-ffi-ext--1.0.sql -- Links SQL function name to the C function in the shared library ('MODULE_PATHNAME') CREATE FUNCTION dpella_sample_random(result FLOAT8, param FLOAT8) RETURNS FLOAT8 AS 'MODULE_PATHNAME', 'pg_dpella_sample_random' LANGUAGE C IMMUTABLE STRICT;// From dpella-ffi/pg_extension/dpella-ffi-ext.c #include <DPella_FFI_stub.h> // Provides declaration for dpella_sample_random_hs PG_FUNCTION_INFO_V1(pg_dpella_sample_random); Datum pg_dpella_sample_random(PG_FUNCTION_ARGS) { // Retrieve the two arguments from PostgreSQL function call float8 arg1 = PG_GETARG_FLOAT8(0); float8 arg2 = PG_GETARG_FLOAT8(1); // Call the Haskell function via FFI double result = dpella_sample_random_hs(arg1, arg2); PG_RETURN_FLOAT8(result); }// From dpella-ffi/src/DPella_FFI.hs -- Exports the wrapped Haskell function under the C name "dpella_sample_random_hs" foreign export ccall "dpella_sample_random_hs" wrappedDpellaSampleRandom :: CDouble -> CDouble -> IO CDouble - Usage (
app/Main.hs):runPostgresExample :: IO () runPostgresExample = do let connStr = "postgres://test:test@localhost:5432/test" -- Connection String putStrLn "\n--- Running PostgreSQL Example ---" PG.runPostgres (BS.pack connStr) $ do -- Establishes connection -- ... (create table, insert data) ... -- Query sum of ages 4 times, to show randomness forM_ [1 :: Int ..4] $ \_ -> do [PG.Only totalAge] :: [PG.Only Double] <- PG.query_ sumQuery -- Executes query using the custom function liftIO $ putStrLn $ "Sum of ages (PostgreSQL): " <> show totalAge - Pros:
- Robust and scalable
- Clear lifecycle management of Haskell runtime via extension hooks
- Cons:
- Complex setup and deployment (C code, FFI, extension build/install)
- Global state in FFI module might have implications
5.3. MySQL
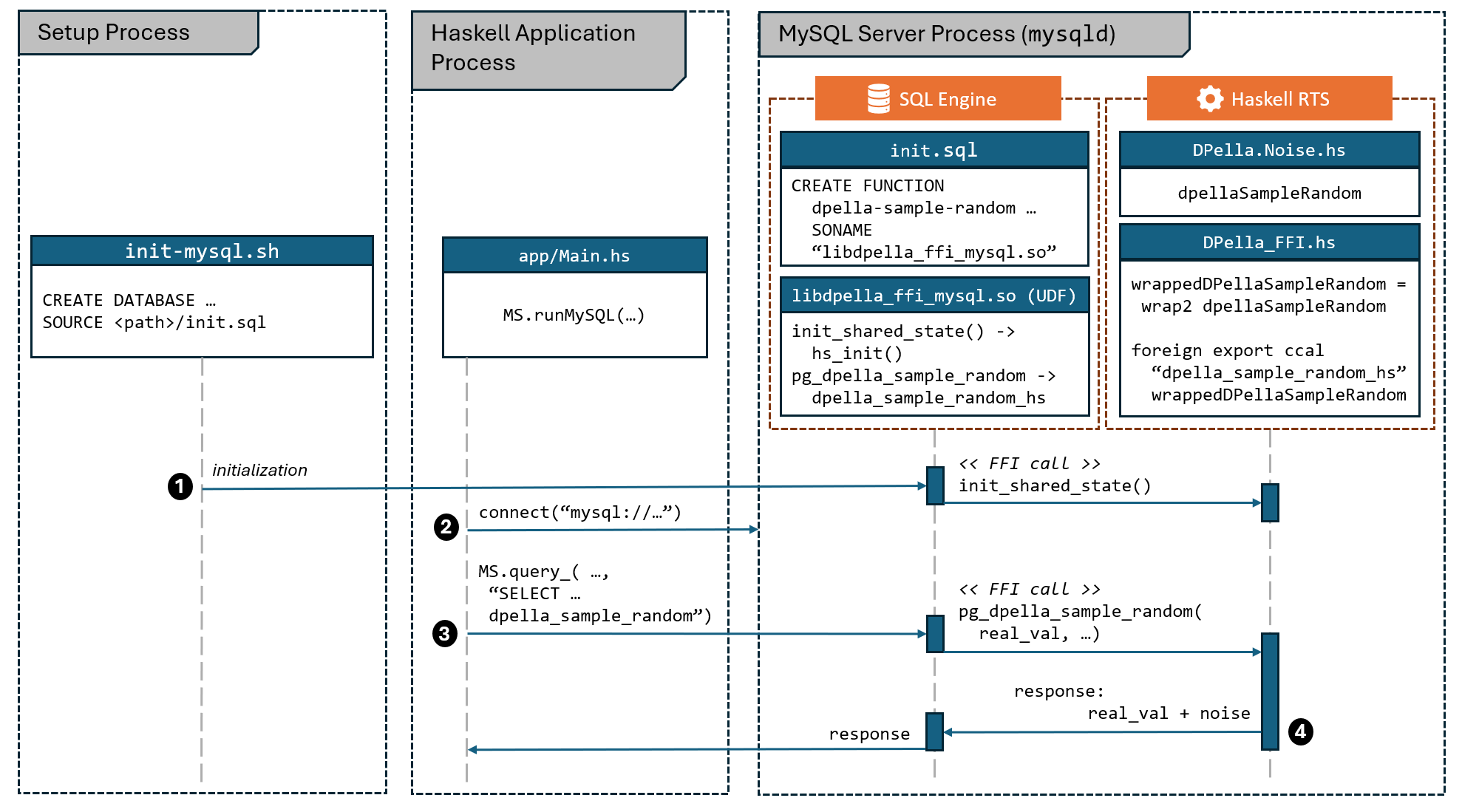
Overview
The MySQL server is initialized and runs as a separate process from the Haskell
application. During initialization, a shared library (libdpella_ffi_mysql.so)
is created that contains the C function dpella_sample_random. This library is
loaded into the MySQL server process. The SQL function dpella_sample_random is
linked to the C function dpella_sample_random via the SQL command CREATE
FUNCTION. The C function calls the Haskell function dpella_sample_random_hs
via the Foreign Function Interface (FFI) which maps to the wrapped
dpellaSampleRandom Haskell function. The Haskell code runs within the Haskell
Runtime System (RTS) inside the MySQL process. The Haskell RTS is lazily
initialized (thread-safe) via init_shared_state() (internally calling
hs_init()) on the first call within the MySQL process.
To execute SQL queries, the application uses the query_ function from the
MySQL client library mysql-simple. Queries referring to the registered SQL
function dpella_sample_random will trigger the execution of the Haskell
function dpella_sample_random_hs within the MySQL process.
Key steps
- Define the SQL function
dpella_sample_randomin the MySQL plugin file (init.sql) via theCREATE FUNCTIONprocedure. - Initialize the Haskell runtime lazily within the MySQL process using
init_shared_state. - Implement the C function
dpella_sample_randomto handle SQL calls and invoke the Haskell functiondpella_sample_random_hsvia FFI.
Details
-
Explanation: The Haskell app connects to the separate MySQL server. An SQL query uses
dpella_sample_random. MySQL maps this (viaCREATE FUNCTION ... SONAME) to the C functiondpella_sample_randomin the loaded shared library (libdpella_ffi_mysql.so). This C function calls the Haskell functiondpella_sample_random_hsvia FFI. The Haskell RTS is lazily initialized (thread-safe) on the first call within the MySQL process. -
Integration: Runs as a separate process. Uses a dynamically loaded UDF (
dpella_ffi_mysql.c) registered viaCREATE FUNCTION ... SONAME ...(init.sql). The C UDF calls the Haskell function via FFI (DPella_FFI.hs). Haskell runtime is lazily initialized on first call with mutex protection (init_shared_state) and persists. State (NoiseGen) is global within the FFI module. - Invocation Mechanism: The SQL function
dpella_sample_randomis linked to the shared librarylibdpella_ffi_mysql.so. MySQL calls the C functiondpella_sample_randomwithin that library for each row. This C function retrieves arguments and calls the Haskell functiondpella_sample_random_hsvia the FFI stub header.-- From dpella-ffi/mysql_plugin/init.sql -- Links the SQL function name to the C function implementation within the shared library CREATE FUNCTION dpella_sample_random RETURNS REAL SONAME "libdpella_ffi_mysql.so";// From dpella-ffi/mysql_plugin/dpella_ffi_mysql.c #include <DPella_FFI_stub.h> // Provides declaration for dpella_sample_random_hs // Main UDF function called per row double dpella_sample_random(UDF_INIT *initid, UDF_ARGS *args, char *is_null, char *error) { // Retrieve arguments double arg1 = *((double*)args->args[0]); double arg2 = *((double*)args->args[1]); // Call the Haskell function via FFI double result = dpella_sample_random_hs(arg1, arg2); *((double*)initid->ptr) = result; // Store result (optional depending on UDF needs) return result; // Return result to MySQL }// From dpella-ffi/src/DPella_FFI.hs -- Exports the wrapped Haskell function under the C name "dpella_sample_random_hs" foreign export ccall "dpella_sample_random_hs" wrappedDpellaSampleRandom :: CDouble -> CDouble -> IO CDouble - Usage (
app/Main.hs):runMySQLExample :: IO () runMySQLExample = do let connStr = "mysql://test:test@localhost:3306/test" -- Connection String putStrLn "\n--- Running MySQL Example ---" MS.runMySQL (BS.pack connStr) $ do -- Establishes connection -- ... (create table, insert data) ... -- Query sum of ages 4 times, to show randomness forM_ [1 :: Int ..4] $ \_ -> do [MS.Only totalAge] :: [MS.Only Double] <- MS.query_ sumQuery -- Executes query using the custom function liftIO $ putStrLn $ "Sum of ages (MySQL): " <> show totalAge - Pros:
- Flexible dynamic loading
- Simpler lazy runtime initialization
- Cons:
- Less structured lifecycle management (no explicit
hs_exittied to UDF unload) - Potential complexity managing global FFI state and concurrency
- Less structured lifecycle management (no explicit
6. Summary of Approaches
| Feature | SQLite | PostgreSQL | MySQL |
|---|---|---|---|
| Integration method | Direct API registration | C Extension + FFI | C UDF + FFI |
| Complexity | Low | High | Medium |
| Scalability | Limited (single process) | High | Medium |
| Runtime management | Simple (App scope) | Explicit (_PG_init) |
Lazy Init (First Call) |
State (NoiseGen) Scope |
Per Connection (SQLEnv) |
Global FFI Module | Global FFI Module |
| Invocation Path | SQL -> sqlite-simple -> Haskell |
SQL -> C Extension -> FFI -> Haskell | SQL -> C UDF -> FFI -> Haskell |
| Best use case | Lightweight domains | Large scale, complex queries | Moderate load |
7. Conclusion
Integrating Haskell functions like dpella_sample_random into SQL databases
demonstrates the flexibility of combining Haskell’s type safety with the
efficiency of relational databases. In this report, we explored the feasibility
of integrating Haskell functions into three different SQL engines, each offering
a unique approach to the integration process tied with different trade-offs:
- SQLite: Best for lightweight, embedded applications with simple integration needs.
- PostgreSQL: Ideal for robust, scalable systems requiring explicit runtime management, however with a more complex setup.
- MySQL: A flexible option for moderate-load applications with dynamic function loading, trading some lifecycle clarity for flexibility.
The choice of approach depends on the specific requirements for scalability, deployment complexity, and state management. By leveraging common Haskell wrapper modules, developers can simplify application-level code while adapting to the operational characteristics of each database engine.